







0 引言
2020年9月中国向全球宣誓,二氧化碳排放力争于2030年前达到峰值,努力争取2060年前实现碳中和。碳排放权交易作为实现“双碳”目标的重要政策工具,其价值作用日益凸显。目前,全球已有20多家碳排放权交易体系在线运行,其中欧盟交易体系(European Union emission trading scheme, EUETS)规模最大、也最成熟,因而也被视为碳排放交易体系的标杆。自2013年以来,我国先后成立了8个试点碳市场,在此基础上,2017年宣布启动全国碳市场建设,并于2021年7月16日正式在发电行业率先启动碳排放权交易。随着碳市场的不断发展,其金融属性日益凸显。碳价格作为碳金融市场的核心指标之一,不仅影响着减排绩效,也影响着减排主体的成本与未来发展。因此,对其作出精准预测不仅有助于为投资者及监管部门提供科学决策依据,还能有效促进碳金融市场的健康发展。
目前有关碳价格预测的研究主要可以分为3类:(1)基于计量模型的预测。文献[1]基于向量自回归模型(vector auto-regression, VAR)预测碳价格;文献[2]基于马尔科夫区制转换(Markov switching auto-regression, MS-AR)模型预测碳价格;文献[3,4]将广义自回归条件异方差模型(generalized auto-regressive conditional heteroscedasticity, GARCH)模型应用于碳价格预测,以刻画碳价格的尖峰厚尾特征。(2)基于人工智能的预测。尽管基于计量模型的预测结果在统计意义上可靠,但却无法捕捉碳价格序列的非线性特征,因此,基于人工智能的算法,如反向传播(back propagation, BP)神经网络[5,6],支持向量机(support vector machines, SVM)[7],最小二乘支持向量机(least squares support vector machine, LSSVM)[8]和极限学习机(extreme learning machine, ELM)[9]被广泛应用于碳价预测。近来,长短期记忆(long-short term memory, LSTM)作为一种新型循环神经网络被广泛应用于碳价预测,并融入了遗传算法(genetic algorithm, GA)、改进鲸鱼优化算法(improved whale optimization algorithm, IWOA)、粒子群优化(particle swarm optimization, PSO)算法等多种优化算法以提高预测精度,但已有研究主要聚焦于LSTM中的参数(如权重矩阵、偏置向量等)优化,几乎没有关于超参数的优化。(3)基于组合模型的预测。考虑到单一预测技术难以满足预测精度要求,因而集成计量模型和机器学习两者优势的组合预测模型越来越受到关注。文献[10]构建了差分自回归移动平均(auto regressive integrated moving average, ARIMA)模型和LSSVM的组合模型预测了欧盟碳排放配额价格。但该研究是基于碳价格原始序列进行的,考虑到碳价格序列不同时间尺度上的异质性,基于分解-集成的建模思路逐渐成为主流。文献[11]基于经验模态分解分解(empirical mode decomposition, EMD)-GARCH模型预测了中国碳价格。文献[8]基于集合经验模态分解(ensemble empirical mode decomposition, EEMD)和LSSVM的集成模型预测碳价格。文献[12]基于CEEMDAN-RBFNN-SVM模型预测中国8个试点市场碳价格。随着数据分解方法的不断演进,EMD中的模态混叠问题得到了很好的改善,然而残差噪声以及虚假模态问题仍未得到有效解决。为此,COLOMINAS [13]对自适应白噪声完备集合经验模态分解(complete ensemble empirical mode decomposition with adaptive noise, CEEMDAN)进一步改进,提出改进自适应白噪声完备集合经验模态分解(improved complete ensemble empirical mode decom-position with adaptive noise, ICEEMDAN)模型,文献[14]发现原始数据序列经过ICEEMDAN分解后的预测结果远优于基于EMD和EEMD分解后的预测结果,这为碳价格预测提供了改进空间。
上述分析表明,尽管碳价格预测取得了丰硕成果,但仍存在改进空间:(1)几乎没有基于ICEEMDAN对碳价格序列进行分解的预测研究;(2)几乎没有集成TGARCH和LSTM两者优势对碳价重构分量进行预测的研究;(3)几乎没有对LSTM超参数进行优化的碳价预测研究。有鉴于此,本文拟构建一种基于分解-集成的碳价格组合预测模型。创新之处在于:(1)采用ICEEMDAN对碳价格原始序列进行分解,克服了EMD和EEMD的缺陷,并进一步采用基于进化聚类算法的综合贡献度指数(comprehensive contribution index, CCI)进行分量重构;(2)采用集成TGARCH和LSTM优势的模型分别对重构分量进行预测:TGARCH预测短期分量,以LSTM预测长期和趋势分量;(3)以布谷鸟搜索(cuckoo search,CS)算法优化LSTM模型中的超参数,以提高预测精度。
1 碳价格多尺度分解集成及预测模型的构建
1.1 ICEEMDAN分解
步骤1 定义Ek(·)为经EMD分解后的第k个模态函数,用EMD方法对i个x(i)=x+β0E1(w(i))取局部均值以获取第1个残差:
式中:M(·)为所分解信号的局部均值的算子;〈·〉表示在整个实现过程中取平均。
步骤2 在k=1时的第1个阶段计算第1个模态为
步骤3 第2个残差为对r1+β1E2(w(i))的局部均值取平均,并定义第2个模态为
步骤4 当k=3,…,K时,残差为
步骤5 第k个模态由下式求出
步骤6 对于后续的每个k,重复步骤4和步骤5的计算过程。
1.2 综合贡献度指数和进化聚类算法
以CCI测度各个分解分量对碳价格原始序列的重要性。假定N个分量,则第p个分量的CCI为
其中:
在分解的基础上,利用进化聚类算法对不同的IMF分量进行聚类重组,聚类过程根据每个模态的CCI指数,把具有相似重要程度的IMF分量汇聚在一起并进行加总,具体算法采用Matlab编程实现。
1.3 长短期记忆神经网络及其超参数优化
1.3.1 长短期记忆神经网络模型
作为一种特殊的循环神经网络(recurrent neural networks,RNN)模型,LSTM模型被设计用以解决在长序列训练过程中出现的梯度爆炸和梯度消失问题。一个LSTM单元由一个储存信息的记忆细胞组成,该细胞的信息更新由3个特殊的“门”实现:输入门、遗忘门和输出门。LSTM单元的内部结构如图1所示。
图1
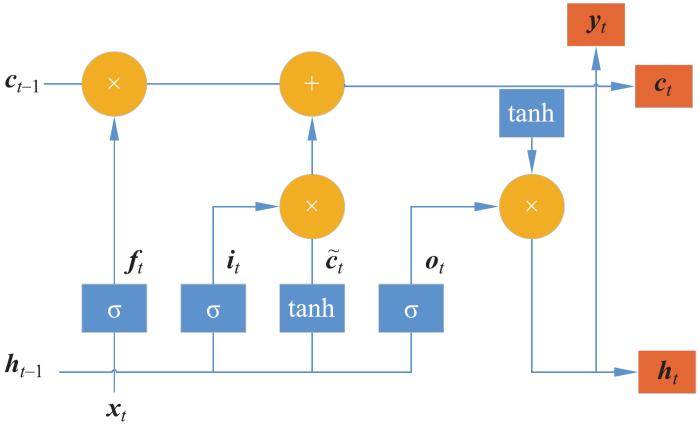
LSTM单元的计算过程可以被分为以下步骤。
(1)计算t时刻的候选记忆细胞状态:
式中:tanh( )表示激活函数双曲正切函数;h(t-1)表示上一时刻的输出向量;x(t)表示预测模型的输入,也就是碳价格的历史数据;Wc和bc分别表示当前记忆细胞的权重矩阵和偏置向量。
(2)计算输入门i(t)的值,输入门决定了当前信息有多少应该被输入到记忆细胞的状态值。
式中:σ(·)表示激活函数sigmoid函数;Wi和bi分别表示输入门的权重矩阵和偏置向量。
(3)计算遗忘门f(t)的值,遗忘门决定前一期的状态c(t-1)有多少信息可以被保存。
式中:Wf和bf分别表示遗忘门的权重矩阵和偏置向量。可以观察到,i(t)和f(t)有相似的形式,而且2个门都由h(t-1)和x(t)决定。
(4)计算当前时刻记忆细胞c(t)的值
式中:c(t-1)是上一期LSTM单元状态的值。记忆细胞的更新取决于上一期细胞和候选细胞的状态取值,记忆细胞的更新由输入门和遗忘门控制。长期信息由f(t)控制,短期信息由i(t)控制。
(5)计算输出门的取值o(t),输出门控制记忆细胞状态取值的输出,即
式中:Wo和bo分别表示输出门的权重矩阵和偏置向量。
(6)计算LSTM单元的输出h(t)
得益于记忆细胞和3个控制门的结构,LSTM模型可以容易地保存、读取、重置和更新长期信息。梯度爆炸和梯度消失的问题在LSTM模型中得到了解决。
1.3.2 超参数优化
(1)超参数。
当学习速率过大时,寻优过程中的参数会在最优解附近变动而非趋近于最优点;当学习速率过小时,模型的收敛速度会变慢。一个迭代就是将所有训练样本训练一次的过程,迭代数量设置的过大,会造成模型过拟合,模型泛化能力不足;迭代次数设置的过小,会造成模型欠拟合,降低预测精度。如果隐藏层节点数过少,模型不能学习到足够的经验;若隐藏层节点过多,会使模型结构变得更复杂,使得网络的收敛速度变慢。本模型设置2层隐藏层,故2个隐藏层各自的节点数计为2个超参数。LSTM模型的上述4个超参数被选择作为应用启发式算法进行寻优的目标。
(2) CS算法。
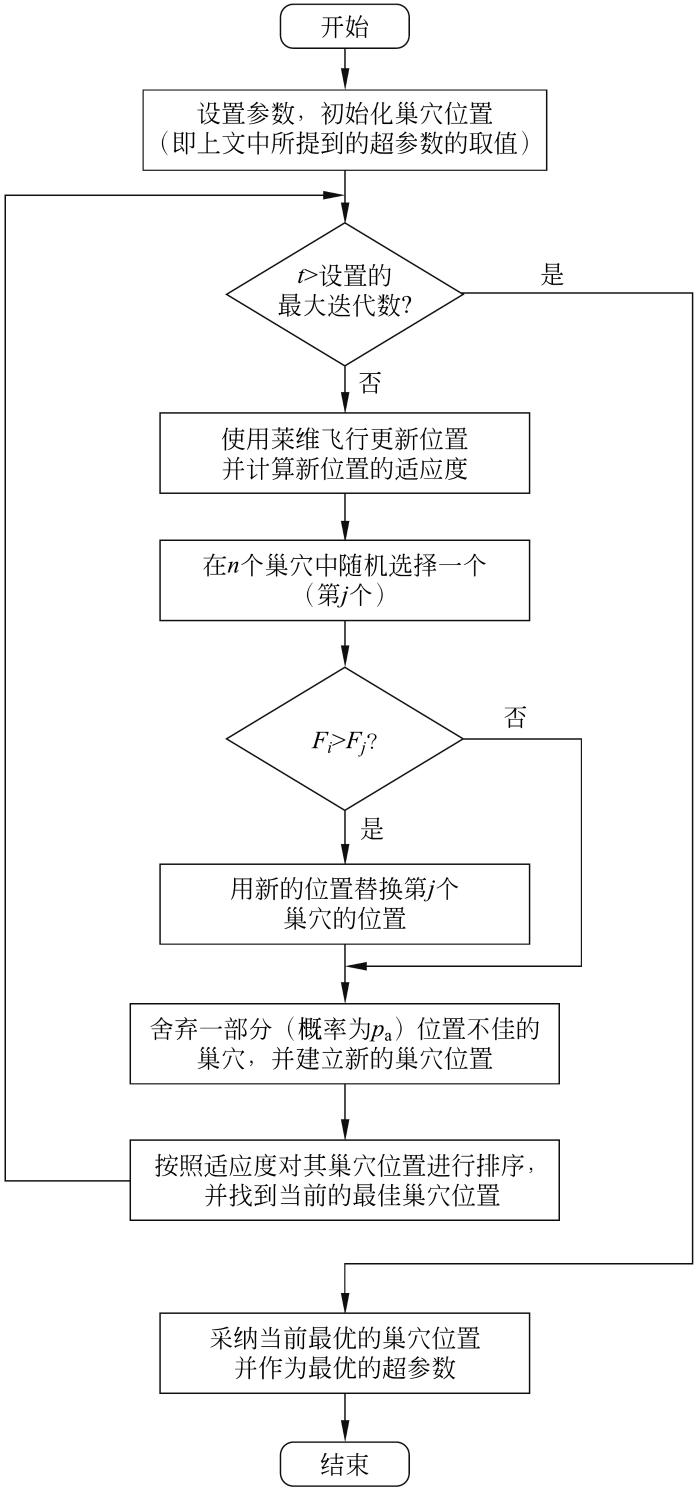
CS算法中有3个理想状态的假设:1)每只布谷鸟一次生下一枚卵并随机选择一个鸟巢进行孵化。2)在一个随机选择的巢群,将最高质量的鸟巢保存作为下一代。3)可利用的鸟巢数目固定,鸟巢拥有者发现外来卵的概率为Pa∈[0,1]。若鸟巢拥有者发现了巢中的外来卵,它将弃置这枚卵并重建一个新巢穴。基于上述3个理想状态,搜索布谷鸟巢穴位置和路径的更新公式如下:
式中:xi,t表示第t次迭代中第i个鸟巢的位置;步长因子α服从正态分布,并且α>0;L(λ)服从莱维随机分布,并定义了莱维随机搜索路径。
在式(
其中:xi,t和xk,t为2个不同的随机序列;H(·)表示Heaviside函数;ε为一个从随机分布中提取的随机数;s表示步长。CS算法的实现过程具体见图2。
图2
1.4 ARMA-TGARCH模型
如果x1, x2,…,xm表示ARMA(p,q)-GARCH(r,s)模型的碳价格观测值,xt可以被解释为
为了刻画金融风险非对称性的特征,Zakoian(1994)提出了TGARCH模型以描述金融市场的起伏波动的回报率。该模型的均值模型和GARCH模型相同,该模型的条件方差可被描述为
式中dt作为名义变量。若εt-k<0,则dt-k=1;若εt-k>0,则dt-k=0。
当价格上升时,
1.5 ICEEMDAN-TGARCH/LSTM(CS)-LSTM(CS)模型构建
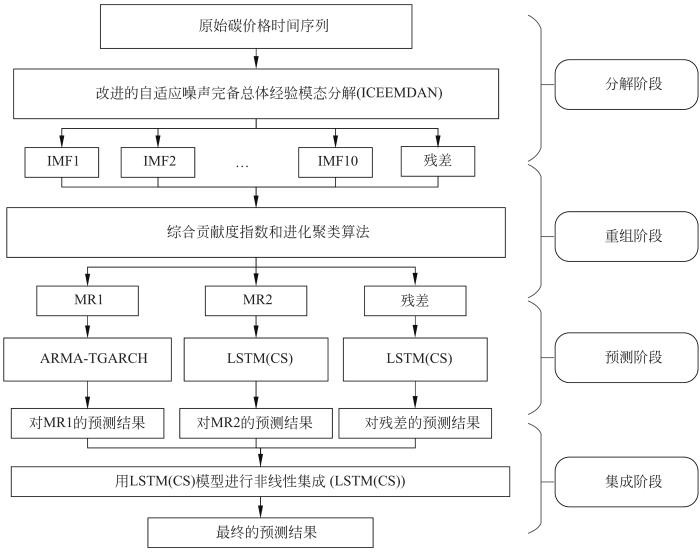
图3给出了组合模型的构建流程。首先,以ICEEMDAN对碳价格原始序列进行分解,并基于CCI指数对分解的各经验模态IMF进行重组,得到短、长期和趋势分量;然后,基于对各分量数据特征的分析,以ARMA-TGARCH预测短期分量,以CS优化超参数的LSTM预测长期分量和趋势分量;最后,对各分量预测值进行非线性集成,得到碳价预测结果,并进行比较分析。
图3
2 实证分析
2.1 样本数据
湖北碳排放权交易市场始于2014年4月2日,截至2021年3月12日,其碳交易量达到78.276万t,交易额达到1 688.347万元。作为交易量和交易额最大的试点碳交易市场,市场机制更完善,价格更具有代表性。因此,本文采用湖北碳市场日度价格数据作为研究样本。样本区间为2015-08-28—2021-04-16,共1 320个样本数据。参照已有研究的样本区间划分设定,将总样本的前90%(2015-08-28—2020-10-20,1 200个样本)作为训练集,将剩余的10%(2020-10-21—2021-04-16,120个样本)作为预测模型的测试集,用来检验模型的预测效果。数据均来源于Wind数据库。
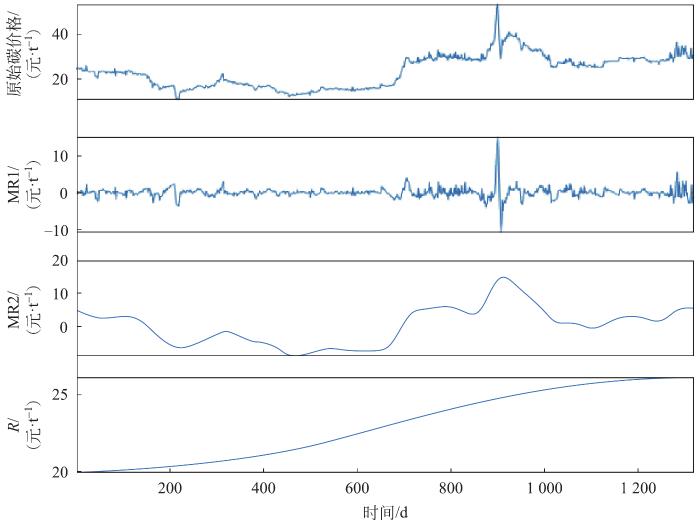
2.2 碳价格序列分解及重构
图4
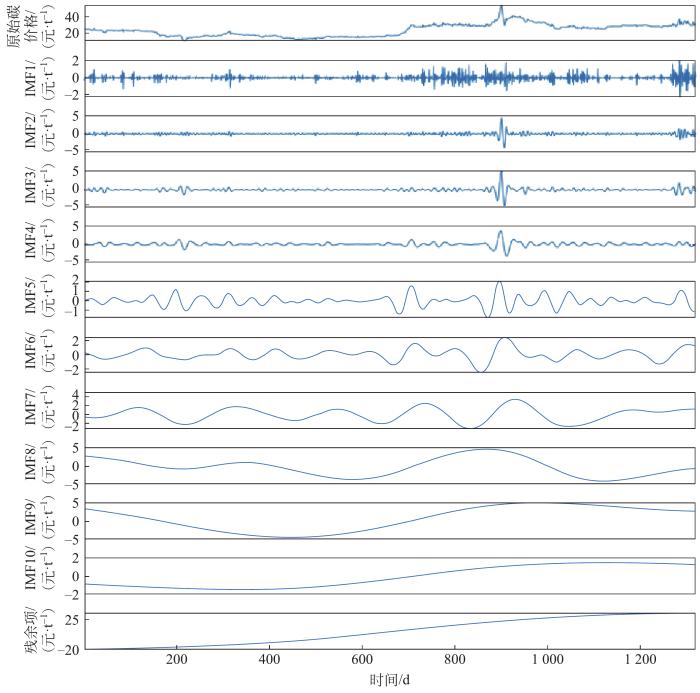
图4
碳价格序列ICEEMDAN分解结果
Fig.4 ICEEMDAN decomposition result of the carbon price series
图5
2.3 碳价格预测
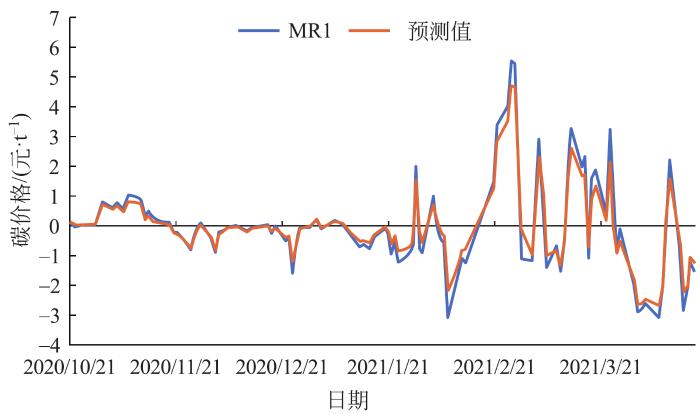
2.3.1 基于ARMA-TGARCH模型的碳价格短期分量MR1预测
表1
| 观测次数 | 均值 | 最小值 | 最大值 | 方差 | 标准差 | 偏态 | 峰度 | JB统计量 | ADF统计量 |
| 1 320 | -0.014 | -10.89 | 15.07 | 1.99 | 1.41 | 2.23 | 32.13 | 58 062.5 | -11.1 |
基于赤池信息量准则(akaike information criterion,AIC),选择滞后阶数,确定ARMA(15,4)模型,以此为基础进行ARCH效应检验,检验结果表明残差序列存在条件异方差,因此可以构建GARCH模型。进一步检验发现GARCH、EGARCH、TGARCH的AIC值分别为1.408 1、1.472 5和1.388 5,基于AIC,选定能反应非对称效应的TGARCH模型为基础,构建ARMA(15,4)-TGARCH(1,2)用于MR1序列的预测,具体见图6。表2是对模型预测效果的评价,表中:MAPE为平均绝对误差百分比;RMSE为均方根误差;MAE为平均绝对误差;TIC为Theil不等系数。
表2
| MAPE/% | RMSE | MAE | TIC/% |
| 61.044 5 | 0.320 01 | 0.217 33 | 0.118 78 |
图6
2.3.2 基于LSTM(CS)模型的碳价格长期分量MR2及趋势分量R的预测
ADF检验表明碳价格长期分量MR2和趋势分量R是非平稳序列,采用偏自相关函数(partial autocorrelation function, PACF)分析选定预测模型的输入变量,具体见表3。
表3
| 重组模态 | 滞后期 |
| MR2 | xt-1,xt-2,xt-3,xt-4,xt-5,xt-6,xt-7,xt-8,xt-9,xt-10,xt-11,xt-12 |
| R | xt-1 |
LSTM模型中的4个超参数,包括迭代次数、学习率、第1隐含层和第2隐含层节点数,本文采用CS确定,结果发现:当学习率为0.003 788,迭代次数为475,第1隐含层和第2隐含层节点数分别为199和64时,MR2预测结果最优;而当学习率为0.004 482,迭代次数为189,第1隐含层和第2隐含层节点数分别为111和128时,R预测结果最好。
2.3.3 预测结果
表4
| MAPE/% | RMSE | MAE | TIC/% |
| 0.715 71 | 0.264 33 | 0.212 53 | 0.444 47 |
图7
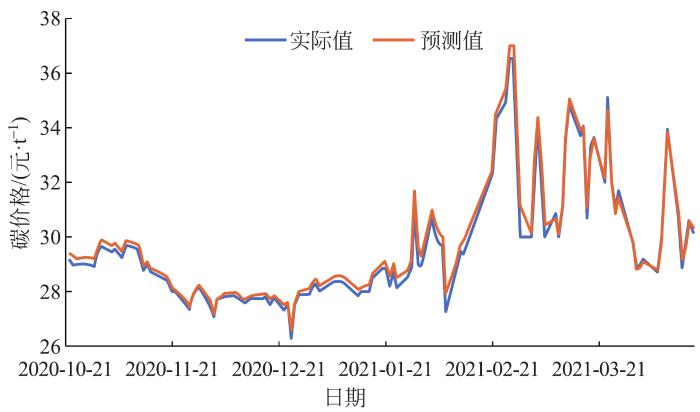
图7
非线性集成方法的碳价格预测结果
Fig.7 Carbon price forecasting result of nonlinear ensemble method
3 实证结果分析
表5
| 比较项目 | MAPE/% | RMSE | MAE | TIC/% |
| (1) BP | 3.344 47 | 1.466 44 | 1.028 19 | 2.467 27 |
| (2) RNN | 2.946 66 | 1.439 96 | 0.895 82 | 2.423 77 |
| (3) GRU | 2.882 17 | 1.431 47 | 0.895 95 | 2.414 7 |
| (4) LSTM | 2.837 34 | 1.405 34 | 0.885 17 | 2.375 87 |
| (5) LSTM(CS) | 1.777 82 | 0.618 99 | 0.534 24 | 1.052 37 |
| (6) ICEEMDAN-TGARCH/ LSTM(CS)-LSTM(CS) | 0.715 71 | 0.264 33 | 0.212 53 | 0.444 47 |
| (7) ICEEMDAN-GARCH/ LSTM(CS)-LSTM(CS) | 0.822 8 | 0.332 66 | 0.250 2 | 0.563 1 |
| (8) ICEEMDAN-LSTM(CS)-LSTM(CS) | 0.907 64 | 0.447 56 | 0.279 85 | 0.756 01 |
| (9) ICEEMDAN-TGARCH/ LSTM(CS)- | 0.764 95 | 0.328 79 | 0.235 56 | 0.555 44 |
| (10) ICEEMDAN-GARCH/ LSTM(CS)- | 0.810 07 | 0.352 45 | 0.249 48 | 0.595 39 |
| (11) ICEEMDAN-LSTM(CS)- | 1.118 44 | 0.460 01 | 0.336 09 | 0.774 52 |
| (12) EMD-LSTM(CS)- | 1.294 15 | 0.636 41 | 0.401 09 | 1.073 85 |
| (13) EEMD-LSTM(CS)- | 1.205 28 | 0.495 24 | 0.367 72 | 0.838 74 |
| (14) CEEMDAN-LSTM(CS)- | 1.131 39 | 0.464 66 | 0.343 09 | 0.787 24 |
| (15) ICEEMDAN-TGARCH/LSTM-LSTM | 0.802 61 | 0.320 23 | 0.244 33 | 0.539 69 |
| (16) ICEEMDAN-GARCH/LSTM-LSTM | 0.832 55 | 0.342 38 | 0.254 2 | 0.577 09 |
| (17) ICEEMDAN-LSTM-LSTM | 1.706 82 | 0.621 73 | 0.508 34 | 1.044 1 |
图8
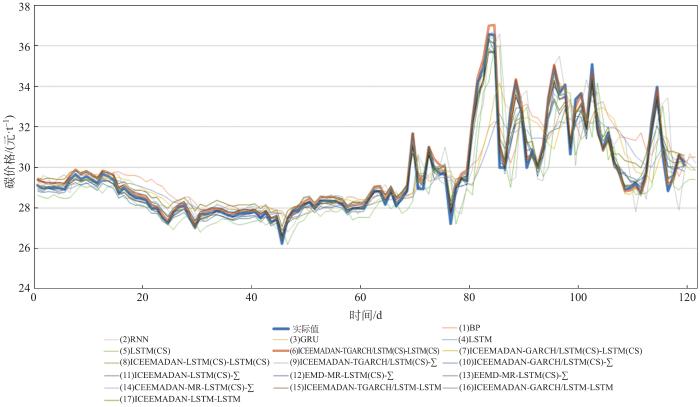
图9
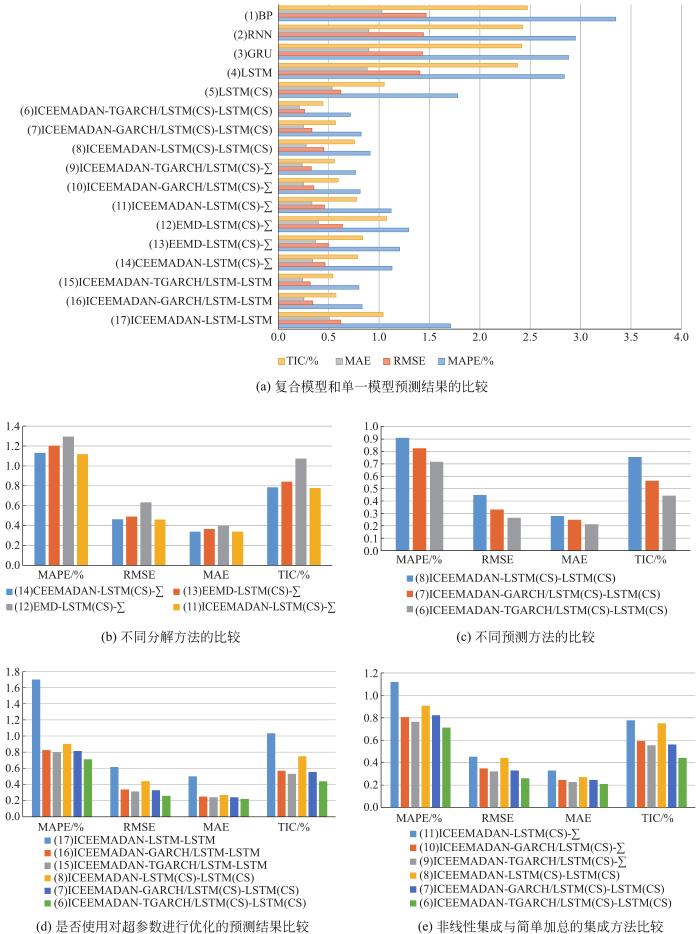
图9
采用不同方法的预测模型的4个评价指标结果(MAPE、RMSE、MAE、TIC)
Fig.9 Four different evaluation criteria of different methods
图9(c)比较了基于人工智能模型和计量经济学的集成模型共同构成的混合方法与单纯基于人工智能模型在预测结果上的不同。结果说明,由于前者能考虑到不同成分是否平稳和频率的不同,更适合预测由具有不同数字特征成分构成的数据。MAPE, RMSE, TIC和MAE这4个预测评价指标显示:包含LSTM(CS)方法和TGARCH方法的集成模型(模型(6))具有最优的预测效果,其优于包含LSTM(CS)模型和标准GARCH模型的混合模型(7),更优于只包含LSTM(CS)方法的模型(8)。其中模型(7)和模型(8)的MAPE指标分别为0.882 8%和0.907 64%,大于所提出的模型(6)。究其原因在于,相对于标准GARCH模型,TGARCH模型考虑到了短期价格震荡的非对称性。除此之外,计量经济学的方法在预测短期的高频分量MR1时,其效果好于单纯的人工智能方法。
图9(d)比较了LSTM模型是否有对超参数优化的CS算法对预测结果的影响。结果表明以CS算法优化LSTM超参数会提升模型的整体预测效果。以MAPE的值来看,所提出的模型(6)对LSTM超参数进行了CS优化,其误差要比未进行CS优化的模型(15)的结果小0.1%。采用LSTM模型的其他复合模型(7)(8)的MAPE、RMSE、MAE和TIC指标也均小于未对LSTM进行CS优化的对照组复合模型(16)(17)。这说明了LSTM(CS)方法相比于LSTM方法显著地降低了预测误差,因此,对LSTM的超参数进行群智能寻优是有意义且有效果的。
图9(e)比较了不同集成方法对预测结果的影响,预测精度结果的评价指标表明,采用LSTM(CS)模型的非线性集成方法要优于传统的简单加和加总的方法。究其原因在于,上述提到的分解集成模型分别预测了每一个分量成分,导致了在简单加和加总过程中会产生误差的累积。当每一个预测结果经非线性集成方法汇总后,会有效地克服上述问题。
上述统计检验结果表明,本文所提出的ICEEMDAN-TGARCH/LSTM(CS)-LSTM(CS)模型在捕获碳价格时间序列特征和对碳价格进行的预测中具有显著的优势。
4 结论
碳金融市场作为应对气候变化、解决碳排放污染问题的有效措施之一,对其价格的精准预测就显得尤为重要。为了进一步提升碳价格预测精度,本文构建了ICEEMDAN-TGARCH/LSTM(CS)- LSTM(CS)碳价组合预测模型。首先采用ICEEMDAN算法对碳价原始序列进行分解,并以CCI指数对分量进行重构,得到短期、长期和趋势分量;然后采用TGARCH预测短期分量,以CS算法优化超参数的LSTM模型预测长期和趋势分量;在此基础上,采用非线性集成算法对各分量预测结果进行集成,得到最终的碳价预测结果。以湖北碳市场为样本数据进行实证分析,结果表明与其他模型相比,所构建的预测模型性能最优。
参考文献
Information linkage, dynamic spillovers in prices and volatility between the carbon and energy markets
[J].
Modeling of carbon credit prices using regime switching approach
[J].
Forecasting carbon futures volatility using GARCH models with energy volatilities
[J].
Modeling and forecasting the volatility of carbon emission market: The role of outliers, time-varying jumps and oil price risk
[J].
Forecasting carbon prices in the Shenzhen market, China: The role of mixed-frequency factors
[J].
Layered feedforward neural network is relevant to empirical physical formula construction: A theoretical analysis and some simulation results
[J].
International carbon market price forecasting using an integration model based on SVR
[C]//DOI:10.2991/emeeit-15.2015.61 [本文引用: 1]
An adaptive multiscale ensemble learning paradigm for nonstationary and nonlinear energy price time series forecasting
[J].
Carbon price forecasting with complex network and extreme learning machine
[J].
Carbon price forecasting with a novel hybrid ARIMA and least squares support vector machines methodology
[J].
The research on setting a unified interval of carbon price benchmark in the national carbon trading market of China
[J].
Carbon trading volume and price forecasting in China using multiple machine learning models
[J].
Improved complete ensemble EMD: A suitable tool for biomedical signal processing
[J].
A hybrid framework for carbon trading price forecasting: the role of multiple influence factor
[J].



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}