






0 引言
现阶段风电功率预测的研究已经较为深入,主要预测方法包括物理方法[3]、统计方法[4]。物理方法计算复杂度高,计算时间长。统计方法能快速、可靠的拟合非线性时序数据而得到广泛应用,可细分为单一模型和组合方法[5]。由于风电出力的不确定性,单一模型会出现局部最优、过拟合等问题。国内外学者将信号分解[6]、特征选择[7]和误差修正[8]等方法与单一模型组合,组合方法解决了单一模型的不足。文献[9]考虑风速对风电出力的影响,用一种改进的经验模态分解法对风速序列进行分解,再通过支持向量机预测分解后数据,得到了较好的预测结果。文献[10]利用优化算法对变分模态分解的参数进行优化,将复杂的风力发电序列分解为简单固有模态函数,对每个简单固有模态函数用长短期记忆网络(long short-term memory, LSTM)进行预测,最后对各分量预测结果求和得到最终预测结果,预测性能有所提升。分解技术与预测模型组合虽然能够一定程度提升精度,但是在分解过程中需要预先设定分量个数,人为因素干扰较大。
风电功率出力受多种特征的影响,因此特征选择技术与预测模型组合的方法逐渐受到学者们关注。文献[11]采用互信息法对特征重要性进行排序,以重要性作为系数修正输入特征,以改进的LSTM对调整后的特征进行预测,取得了较好的预测结果。文献[12]先用互信息法对数据进行相关性排序,再加入特征淘汰机制,在特征选择过程中有效剔除了冗余特征。文献[13]利用最小冗余最大相关性法对各种日类型、温度、气象条件等特征进行相关分析,得到最佳特征集。再将最佳特征集放入优化后的一般回归神经网络中进行预测,有效提高了预测精度。文献[14]用皮尔逊相关系数对特征进行自适应选取,再将选取后的数据当作输入用预测模型进行预测。经特征选择后,可有效降低计算复杂度,提高预测精度。
预测模型始终伴随着误差的存在,因此误差修正技术与预测模型的组合也得到了广泛应用。文献[15]提出将深度学习模型与误差修正结合,先采用深度学习模型对风功率进行预测得出误差,再用随机森林对误差进行预测,对初步结果进行误差修正。文献[16]采用LSTM预测误差,对初始的预测结果进行误差校正。文献[17]将误差值作为输入,利用卷积神经网络(convolutional neural networks, CNN)-LSTM模型预测误差,利用误差预测结果对初始预测数据进行补偿,取得了更高的预测精度。文献[18]采用一种改进的极端梯度提升对风功率预测进行初步预测并将误差数据分为3类,用随机森林来分别训练这3类误差,将所得结果与初步预测值相加得出最终预测结果,提高预测精度。
上述特征选择方法主要以自身参数设定来选择输入特征,并未考虑与预测模型的适配性。误差数据作为单变量,数据量小,目前的研究中多以机器学习算法来预测误差,往往会面临训练数据不够、参数难以设置的问题。基于此,本文提出一种正交化最大信息系数(orthogonalization maximal information coefficient, OMIC)与预测模型结合的特征选择方法,该方法通过OMIC对特征进行重要性排序后,根据不同预测模型选出对应模型的最优特征集,充分的挖掘风机特征与风机出力的相关性。在此基础上,利用动态模态分解(dynamic mode decomposition, DMD)跟踪这些模型所产生的误差数据的时空模态,并以此来预测误差。
1 算法原理
1.1 正交化最大信息系数
仅考虑2个变量之间的相关度来选择特征可能导致相互之间有较大的冗余信息。文献[19]提出一种将施密特正交化(gram-schmidt orthogonalization, GSO)和最大信息系数(maximal information coefficient, MIC)结合在一起的OMIC算法以达到特征选择时的最大相关性和最小冗余。OMIC算法实现的步骤如下。
对于由2个变量X和Y组成的二维数据集D(X,Y),将X和Y沿着各自坐标轴方向在二维空间上划分为X0和Y0的区间数,形成了X0×Y0的网格G。定义D|G为二维数据集D(X,Y)在网格G上的分布。根据D|G的分布,X和Y的互信息定义为
式中:p(i,j)为联合概率,代表D(X,Y)在i和j所划分出的网格中的落入情况;p(i)和p(j)为边缘概率,分别代表二维数据集D(X,Y)落在第i个水平区间和第j个垂直区间的比例。
对于数据集D(X,Y),相同的i和j也会产生多种不同的网格G,因此也会产生不同分布的D|G。MIC就是从这些网格G中找到互信息最大值作为输出。最大的互信息I(D,X0,Y0)定义为
式中I(D|G)表示D(X,Y)的互信息。
建立归一化的特征矩阵M,其组成元素为
则MIC表达式为
式中:n为样本总数;B(n)表示网格所能划分数量的上限。文献[20]中提出B(n)=n0.6时能够取得最好的效果,本文采用一样的设置。
设变量集S=
图1
式中MIC(GSO(xk+1,Sk),t)求取xk+1独立于已选变量集Sk的特征信息与目标变量t之间的最大信息系数值,GSO(xk+1,Sk)是待选变量xk+1相对于已选变量集Sk的施密特正交化量,通过施密特正交化方法可以有效排出无关冗余,使其不会出现在OMICS评分系统中。GSO(xk+1,Sk)计算式为
式(
则k次变量选择后的集合Sk定义为
待变量全部选完后,按变量放入集合的顺序即可得到考虑相关性与去除无关冗余的变量重要性排序。
1.2 DMD
DMD最初是在计算流体动力学领域引入的,用于从时空复杂流体流数据中提取相干结构。DMD可根据时间序列数据计算一组模态,每个模态都与一个复特征值相关联。因此,利用DMD,一个非线性系统可以用由特征值控制的模态的叠加来描述。DMD预测单变量时间序列[21],包括4个阶段。
(1)构建汉克尔矩阵。
设有一组长度为T的单变量时间序列数据X=
式中2≤L≤
(2)动态模态分解。
K滞后向量
式中U∈CK×r,V∈C(L-1)×r,U、V均为酉矩阵,Σ∈Cr×r为奇异值对角阵,H为共轭转置,r为通过奇异值分解降维后的秩。
综合上述等式,可以得出A如下式:
式中+为求广义逆,在实际应用中,计算相似矩阵
对
式中:W为
由于
将离散的λk进行连续化处理:
(3)重构。
轨迹矩阵X可由DMD模态重构,设重构后的轨迹矩阵为
式中b=Φ+
(4)预测。
为了预测长度为F的时间序列,将重构后的轨迹矩阵
在
式中Re(·)指取各元素的实部,Dn={(i,j):1≤i≤K,1≤j≤F,i+j=n+1},num(·)为(i,j)的组合数个数。
最终得到的预测时间序列为
2 基于OMIC-深度学习-DMD的预测模型
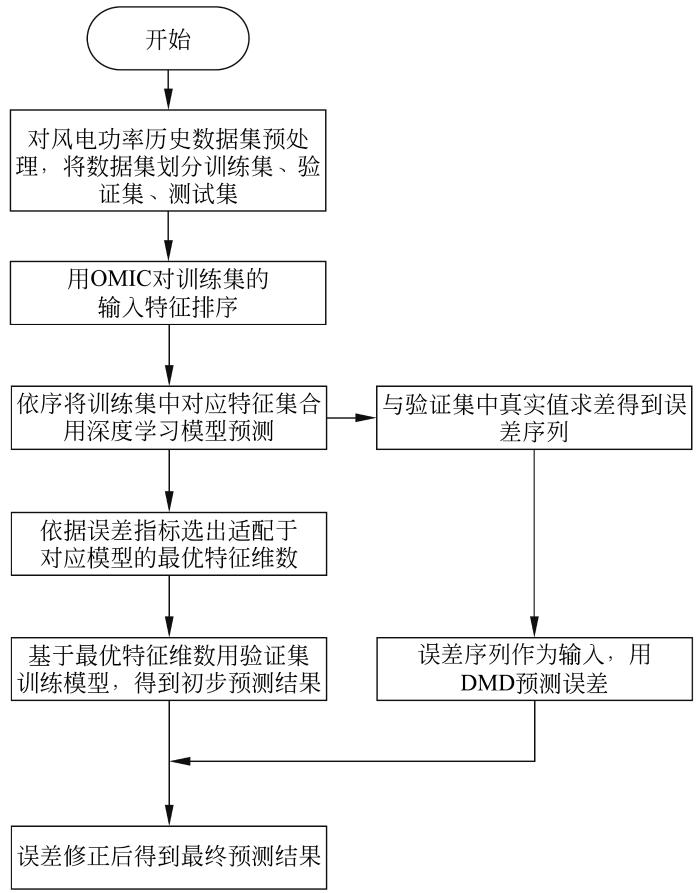
风机发出的功率受风速、风向、环境温/湿度、叶片角度等特征影响,具有高度复杂的非线性特征。本文利用OMIC对风机相关特征进行排序,将排序后的特征与不同深度学习预测模型结合进行预测,根据相关指标选出适配于各模型的最优特征集合。在选出最优特征集合之后,利用该集合训练模型求得预测值,从而得到对应模型预测后所产生的误差值,利用DMD捕捉误差值的波动趋势特征来预测误差序列,将其与风电功率初步预测结果相加得到最终预测结果。基于OMIC-深度学习-DMD的预测模型框架如图1所示。
3 算例分析
以我国北方某风电场单台风机连续一个月(4 320个数据点)的实测数据集作为研究对象,每个数据点间的分辨率为10 min,风机的装机容量为1 600 kW。数据集包括影响风机发电的关键外部特征,如风速、风向和外部温度;基本的内部特征,如叶片的内部温度、机舱方向和俯仰角;以及风机的实际有功功率出力,具体见表1。
表1 风机特征
Table 1
| 特征简称 | 特征 |
| Ws | 风速/(m·s-1) |
| Wd | 风向与涡轮机间角度/(°) |
| Et | 风机所处环境温度/℃ |
| It | 涡轮机舱内温度/℃ |
| Nd | 机舱偏航角/(°) |
| Pa1 | 叶片1的桨距角/(°) |
| Pa2 | 叶片2的桨距角/(°) |
| Pa3 | 叶片3的桨距角/(°) |
3.1 数据归一化及预测评价指标
由于数据集中各特征单位不同,为避免因数量级差异过大带来的误差,需对数据进行归一化。采用计算公式(
式中x′为归一后数据,x为需归一化的特征数据,xmax为对应特征中的最大值,xmin为对应各特征中的最小值。
为了定量的评估预测模型,本文预测误差评价指标采用标准均方根误差(normalized root mean squared error,NRMSE)与标准平均绝对误差(normalized mean absolute error,NMAE),各指标的计算公式如式(
式中:P为装机容量;N为预测段的样本总数;yi为风电功率真实值;
3.2 仿真结果分析
将实测数据按2∶2∶1的比例分为风电功率预测训练集、验证集与测试集,将训练数据用于OMIC算法进行特征排序。综合考虑各特征与有功功率间的相关度以及最小冗余,得到最优排序的特征集。随后将训练数据按OMIC特征排序结果依次组成集合输入预测模型中,用验证集得出预测误差指标进一步精选出适配于各模型的输入特征维数。经OMIC排序后的特征见表2。
表2 经OMIC排序后特征
Table 2
| 排序 | 特征 |
| 1 | 风速 |
| 2 | 叶片3的桨距角 |
| 3 | 风机所处环境温度 |
| 4 | 叶片2的桨距角 |
| 5 | 叶片1的桨距角 |
| 6 | 涡轮机舱内温度 |
| 7 | 风向与涡轮机间角度 |
| 8 | 机舱偏航角 |
根据上表OMIC排序结果,将训练集中特征依序组成集合作为输入,用深度学习模型进行预测。根据验证集计算误差指标,作为特征选择的依据。本文分别考虑了OMIC与循环神经网络(recurrent neural network,RNN)、LSTM、门控循环单元(gated recurrent unit,GRU)相结合的3种组合预测模型确定其最优特征维数。仿真结果如图2所示。
图2
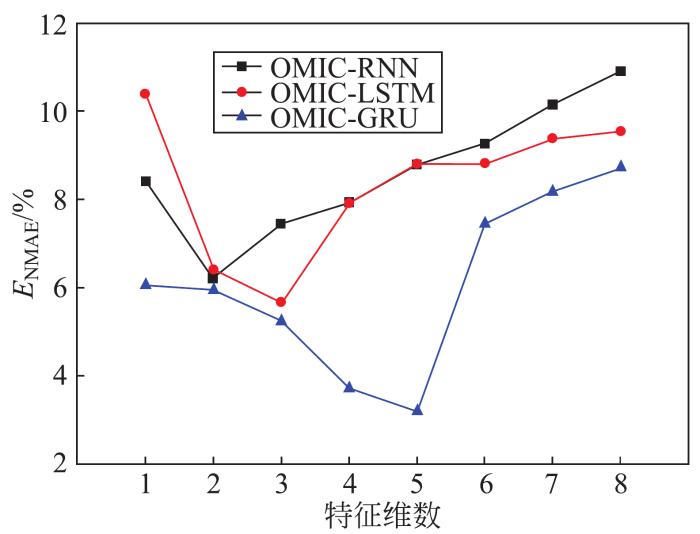
图2
模型输入特征维数与NMAE关系
Fig.2
Relationship between model input feature dimension and NMAE
表3 不同模型特征选择结果
Table 3
| 特征选择模型 | 最优特征维数 | 选择的特征 |
| OMIC-RNN | 2 | Ws,Pa3 |
| OMIC-LSTM | 3 | Ws,Pa3,Et |
| OMIC-GRU | 5 | Ws,Pa3,Et,Pa2,Pa1 |
在此基础上,将测试集数据,按最优特征维数输入训练好的深度学习模型中,得到风电功率预测结果。与验证集中真实数据对比求出误差序列。随后用DMD捕捉误差序列的动态趋势,预测下一阶段各模型误差。
图3
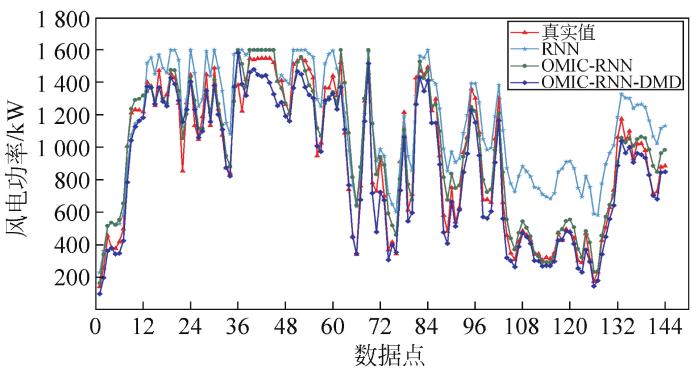
图4
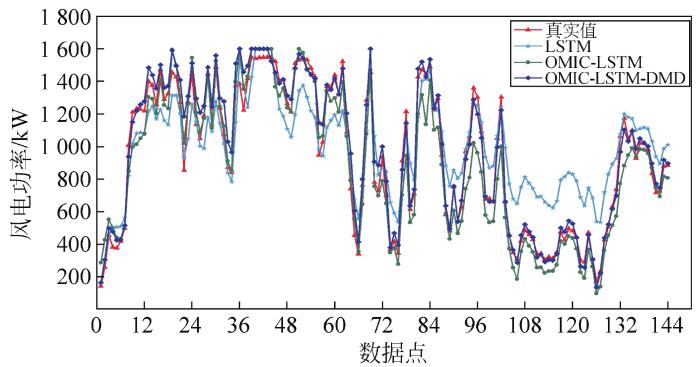
图5
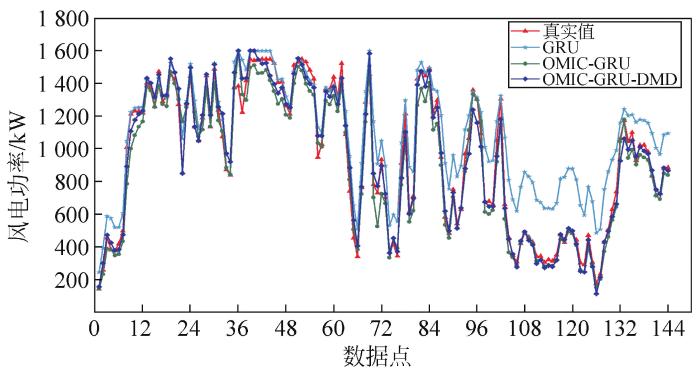
表4 不同模型预测误差对比
Table 4
| 模型 | ENMAE | ENRMSE |
| RNN | 10.2 | 13.35 |
| OMIC-RNN | 6.13 | 8.05 |
| OMIC-RNN-DMD | 4.83 | 5.98 |
| LSTM | 8.26 | 11.12 |
| OMIC-LSTM | 5.18 | 6.69 |
| OMIC-LSTM-DMD | 3.67 | 5.22 |
| GRU | 8.57 | 11.38 |
| OMIC-GRU | 3.15 | 4.48 |
| OMIC-GRU-DMD | 3.03 | 4.35 |
对比表4中预测误差指标可以看出,OMIC结合预测模型可以有效选出适用于不同深度学习预测模型的特征维数。经特征选择后,不同的深度学习模型均表现出更高的风电功率预测精度,有良好的稳定性和适应性。利用DMD来预测下一时段误差,为风电功率预测提供修正值的误差修正方法也能良好地适配不同模型。以NMAE为预测误差评价指标时,3种特征选择后的模型在误差修正后精度分别提高1.3%、1.51%和0.12%。以NRMSE为预测误差评价指标时,经误差修正后的3种特征选择后模型精度分别提高2.07%、1.47%和0.13%。综上所述,本文所提方法在风电功率预测中能够提升预测精度,且能适用于不同预测模型。
4 结论
本文所提的特征选择方法能够有效地选择出适用于对应深度学习模型的特征集合,降低了计算复杂度,提升了预测精度。
此外,为有效地捕获误差序列的动态趋势,实现准确的误差预测。本文利用一种数据驱动的方法DMD来预测误差序列,DMD可有效捕捉误差序列的动态趋势,且无需考虑输入特征和选择参数,在预测误差时更容易实现。最终提出一种OMIC-深度学习-DMD的风电功率预测模型,相比与其他预测模型,本文所提的模型预测出的结果更接近真实值,具有更高的预测精度,仿真结果验证了所提模型在风电功率预测中的优越性、有效性。
参考文献
风电功率预测关键技术及应用综述
[J].
Review on key technologies and applications in wind power forecasting
[J].
基于VMD-SE和机器学习算法的短期风电功率多层级综合预测模型
[J].
Short-term wind power multi-leveled combined forecasting model based on variational mode decomposition-sample entropy and machine learning algorithms
[J].
考虑气象特征与波动过程关联的短期风电功率组合预测
[J].
Combined prediction of short-term wind power considering correlation of meteorological features and fluctuation process
[J].
基于长短时记忆网络的超短期风功率预测模型
[J].
Ultra-short-term wind power prediction model based on long and short term memory network
[J].
基于PCA-LSTM模型的风电机网相互作用预测
[J].
Prediction of interaction between grid and wind farms based on PCA-LSTM model
[J].
Short-term load forecasting based on the CEEMDAN-sample entropy-BPNN-transformer
[J].
按时序特征优化模型后在线选配的超短期风电预测
[J].
An ultra-short-term wind power prediction method using “offline classification and optimization, online model matching” based on time series features
[J].
计及误差反馈的短期风电功率预测
[J].
Short-term wind power forecast considering error feedback
[J].
基于聚类经验模态分解和最小二乘支持向量机的短期风速组合预测
[J].
A hybrid model for short-term wind speed forecasting based on ensemble empirical mode decomposition and least squares support vector machines
[J].
A wind power forecasting method based on optimized decomposition prediction and error correction
[J].
考虑特征重要性值波动的MI-BILSTM短期负荷预测
[J].
Short-term load forecasting based on mutual information and bi-directional long short-term memory network considering fluctuation in importance values of features
[J].
基于特征选择与多层级深度迁移学习的风电场短期功率预测
[J].
Short-term wind power prediction based on feature selection and multi-level deep transfer learning
[J].
Short term load forecasting based on feature extraction and improved general regression neural network model
[J].
基于小波深度置信网络的风电爬坡预测方法
[J].
Wind power ramp prediction algorithm based on wavelet deep belief network
[J].
基于深度学习与误差修正的超短期风电功率预测
[J].
Ultra-short term wind power prediction based on deep learning and error correction
[J].
基于多目标优化和误差修正的短期风速预测
[J].
Short-term wind speed prediction based on multi-objective optimization and error correction
[J].
基于特征交叉机制和误差补偿的风力发电功率短期预测
[J/OL].
Short-term wind power prediction based on feature crossover mechanism and error compensation
[J].
基于误差修正的短期风电功率集成预测方法
[J].
Short-term wind power integration prediction method based on error correction
[J].
A filter feature selection method based on the maximal information coefficient and gram-schmidt orthogonalization for biomedical data mining
[J].
Detecting unbiased associations in large data sets
[J].
A data-driven strategy for short-term electric load forecasting using dynamic mode decomposition model
[J].



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}